Predicted-Latency Based Scheduling for LLMs
· 28 min read




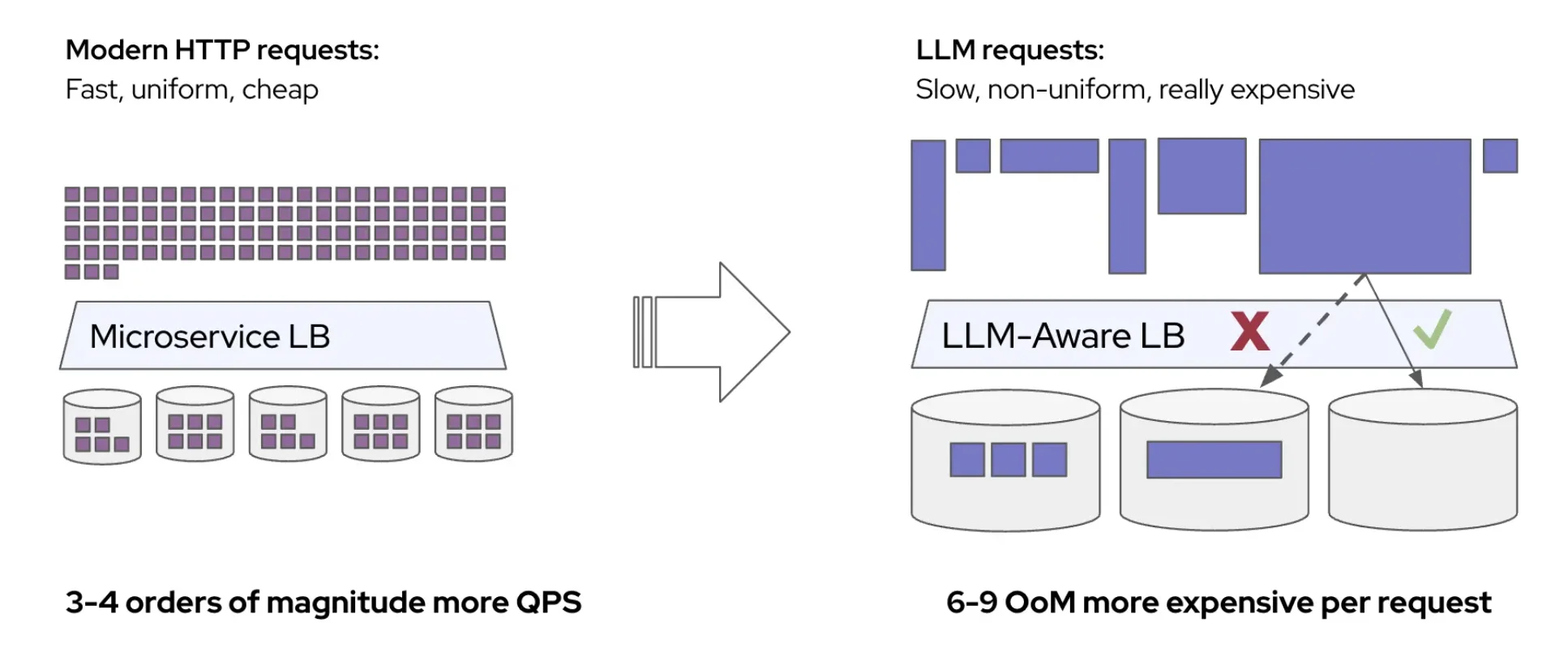
Not all LLM requests cost the same. A short prompt might complete in milliseconds, while a long one can occupy a GPU for seconds. If we can predict how long a request will take on each candidate server before dispatching it, we can make substantially better routing decisions. This post describes a system that does exactly that: a lightweight ML model trained online from live traffic that replaces manually tuned heuristic weights with direct latency predictions.